Blogs

Marcial Calvo Valenzuela
One of the most common needs that we face in Liferay Portal / DXP installations is the monitoring, as well as the alert system that alerts us if something does not work as it should (or as expected)
Whether it is a web service managed in the cloud, a virtual machine, or a Kubernetes cluster, we need to monitor the entire infrastructure in real time and even have a history. In order to mitigate this need, Grafana was developed.
Grafana is a free software based on the Apache 2.0 license, which allows the display and formatting of metrics. With it we can create dashboards and charts from multiple sources. One such font type is Prometheus.
Prometheus is an open source software that enables metric collection via HTTP pull. For the extraction of these metrics it is necessary to have exporters to extract the metrics from the desired point. For example, for the Kubernetes cluster metrics we could use kube-static-metrics. In our case, we want to monitor Liferay Portal / DXP, which in an on-premise installation we would do it through the JMX protocol using tools such as JConsole, VisualVM to do it hot or using an APM that extracts and persists this information in order to have of a history of the behavior of the platform. In this case we will use JMX Exporter, through which we will extract the mBeans from the Liferay Portal / DXP JVM so that Grafana can then read them, store them and with them create our dashboards and alerts.
We will also use the Kubernetes container Advisor (cAdvisor) to obtain the metrics that the cluster exposes about our containers.
Requirements
- A Kubernetes cluster
- Liferay Portal / DXP deployed on Kubernetes. If you don't have it, you can follow the following blog I did a few months ago to deploy Liferay Portal / DXP on Kubernetes.
Let's start!
Configuring Exporter JMX for Tomcat
The first thing we will do is extract the metrics by JMX from the Tomcat of our Liferay Portal / DXP. For this we will use the JMX exporter. We will execute this exporter as a javaagent within the JVM Opts of our Liferay Portal / DXP.
- Using our Liferay Workspace, we add the jmx folder and in it we include the javaagent .jar and the yaml file to configure the exporter. In this yaml file we are including some patterns to extract the mBeans as metrics: counters to monitor tomcat requests, about the session, servlets, threadpool, database pool (hikari) and ehcache statistics. These patterns are fully adaptable and extensible for any needs that may arise.
Next we will need to build our Docker image and push it to our registry to update our Liferay Portal / DXP deployment with our latest image, or else configure our Liferay Portal / DXP image with a configMap and volume to add this configuration. - Using the environment variable LIFERAY_JVM_OPTS available in the Liferay Portal / DXP Docker image, we will include the necessary flag to execute the javaagent. Following the documentation of the JMX exporter we will need to define the port in which we will expose the metrics and the configuration file with our mBeans export patterns. In my case, I have included this environment variable using a configMap where I group all this type of environment variables, but it could be inserted directly into the Liferay Portal / DXP deployment:
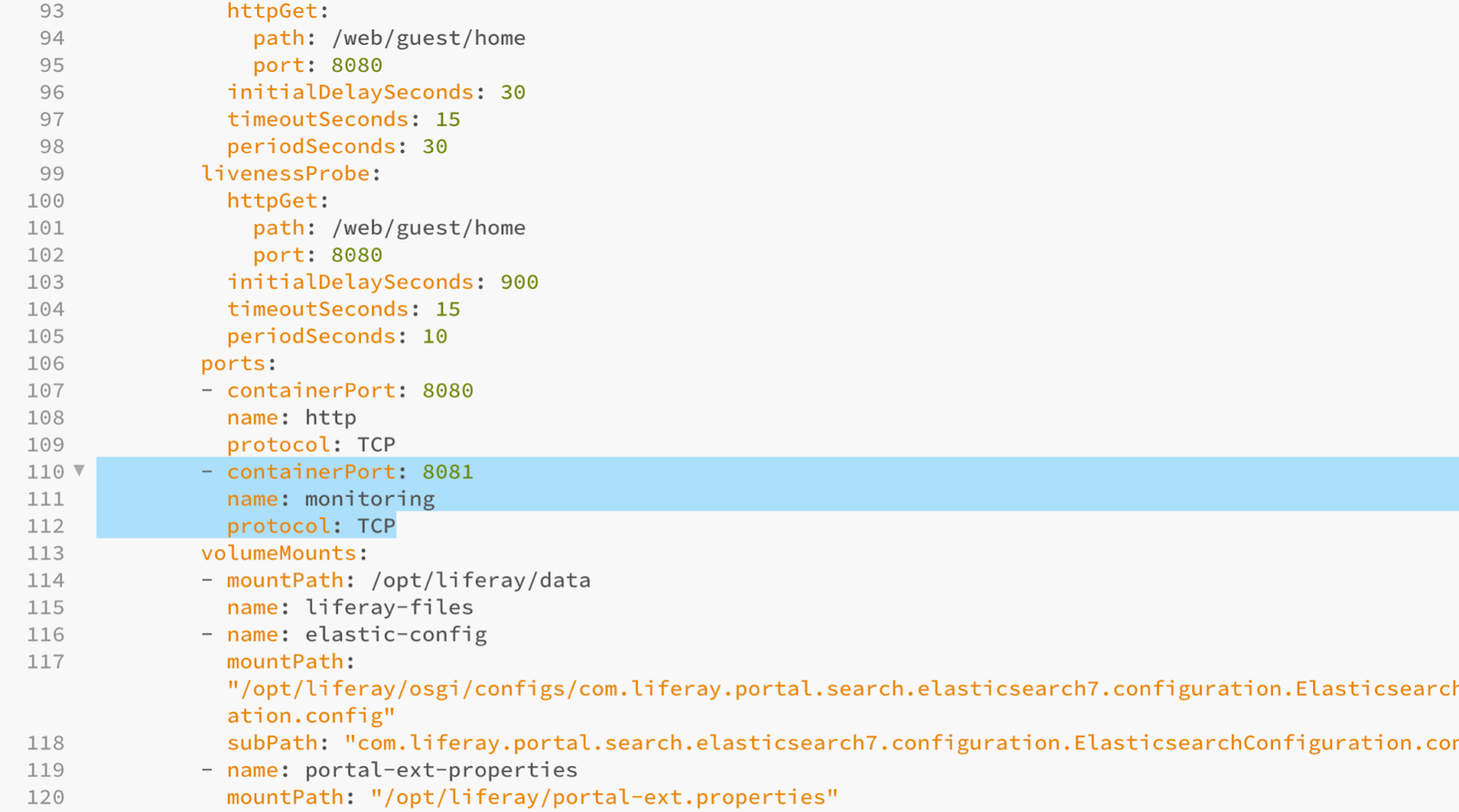
We will open port 8081 to the container, calling it “monitoring” and we will include the necessary annotation so that Prometheus hooks the metrics to the pods that run this type of container, as well as indicate the port on which it will extract the metrics so that Prometheus hooks only with this port:
With this configuration, we will be able to start our first Liferay Portal / DXP pod and on port 8081 we will have an endpoint “/metrics” where the configured metrics are being exposed. If we wanted to query it, we could open a nodePort to port 8081 to access it, but it is not necessary.


Installing Prometheus
Now we will install Prometheus in our cluster:
- First of all we will need to create the namespace where we will implement Prometheus. We will call it "monitoring".
Next, we will include the cluster resources to monitor. We will need to apply the following yaml manifest, with which we will create the role "prometheus" and associate it with the namespace "monitoring". This will apply the "get", "list" and "watch" permissions to the cluster resources listed in "resources". In our case, we will add the pods and k8s nodes. The pods to access the endpoint "/metrics" where our JMX exporter is exposing metrics and the nodes to be able to access the CPU and Memory requested by our Liferay Portal / DXP containers:
- We will need to create the following configMap to configure our Prometheus. In it we will indicate the configuration of the job that will scrape the metrics that the Exporter JMX is generating in each Liferay Portal / DXP pod in addition to the job that will extract the metrics from the Kubernetes Advisor container, in order to monitor CPU and Memory of The containers. In it, we also indicate that the interval to read these metrics is 5s:
- Now we will deploy Prometheus in our namespace monitoring. First we will create the PVC where Prometheus will store its information and then we will apply the yaml manifest with the Prometheus deployment. In it we include the previous configuration made in step 2 and open port 9090 to the container.
- We will then create the Service that will expose our Prometheus instance to access it. In this case we will use a nodePort to access the destination port:
- And once deployed ... if we access the IP of our cluster and nodePort 30000 we will see Prometheus:
- Accessing targets (http: // <ip>: 30000 / targets) we will see the status of our pods configured to export metrics. In our case, a single pod with Liferay Portal / DXP:
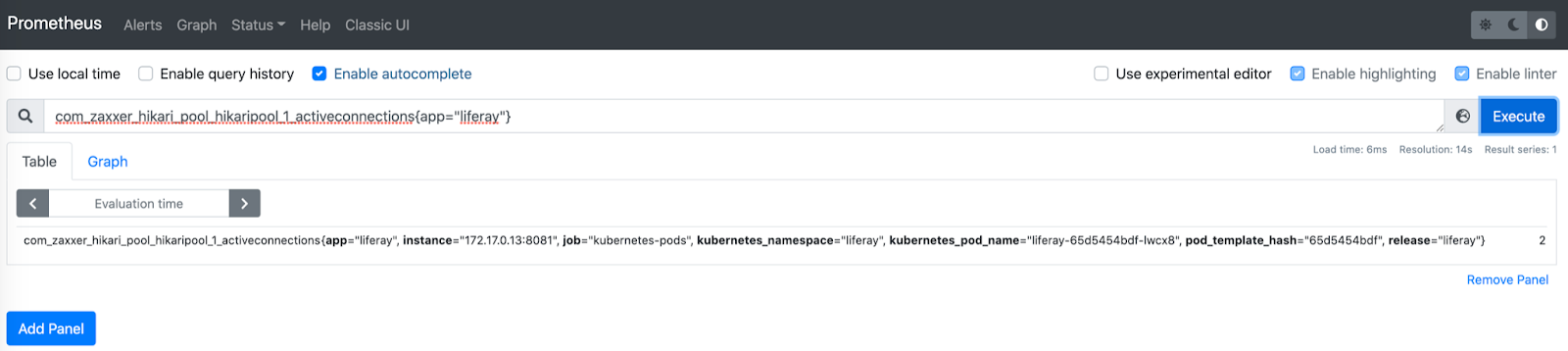
- From the main Prometheus page, we can insert the queries to extract the desired metrics. These queries must be in PromQL format. To learn a little more about this Query Language, you can read the basics from the official Prometheus website and pick up some examples:
If we look at the output of the query, we can see, in addition to its output value, the origin of the metric: the pod name, namespace, ip, release name (in case we use HELM for its deployment, etc) We can also consult the output of the metric in the form of a graph:






Installing and configuring Grafana
Grafana is the metric analysis platform that allows us to consult and create alerts on the data obtained from a metric source, such as our Prometheus. Grafana's strong point is the creation of very powerful dashboards that are totally tailored and persistent over time, which can also be shared. The creation of alerts through many channels such as email, slack, sms, etc. is also a very powerful point.
As we have done with Prometheus, we will need to install Grafana on our k8s Cluster. We will carry out the Grafana deployment in the same namespace monitoring.
- We will create the following configMap in the "monitoring" namespace that will help us to apply the necessary configuration to Grafana to connect with Prometheus. Basically what we do in it is create a datasource whose endpoint is the Prometheus service created previously: prometheus-service.monitoring.svc: 8080
- We will create the PVC where Grafana will store the information with the following manifest yaml
- We will create the Grafana deployment in "monitoring" applying the following manifest. In it we open port 3000 to the container.
- We will create the service that Grafana will expose and we open port 3000 through a nodePort to 32000 of our cluster:
- Now we can access to our Grafana instance:
- Will do login with the default administrator user (admin and password admin) and we can start creating our dashboards:
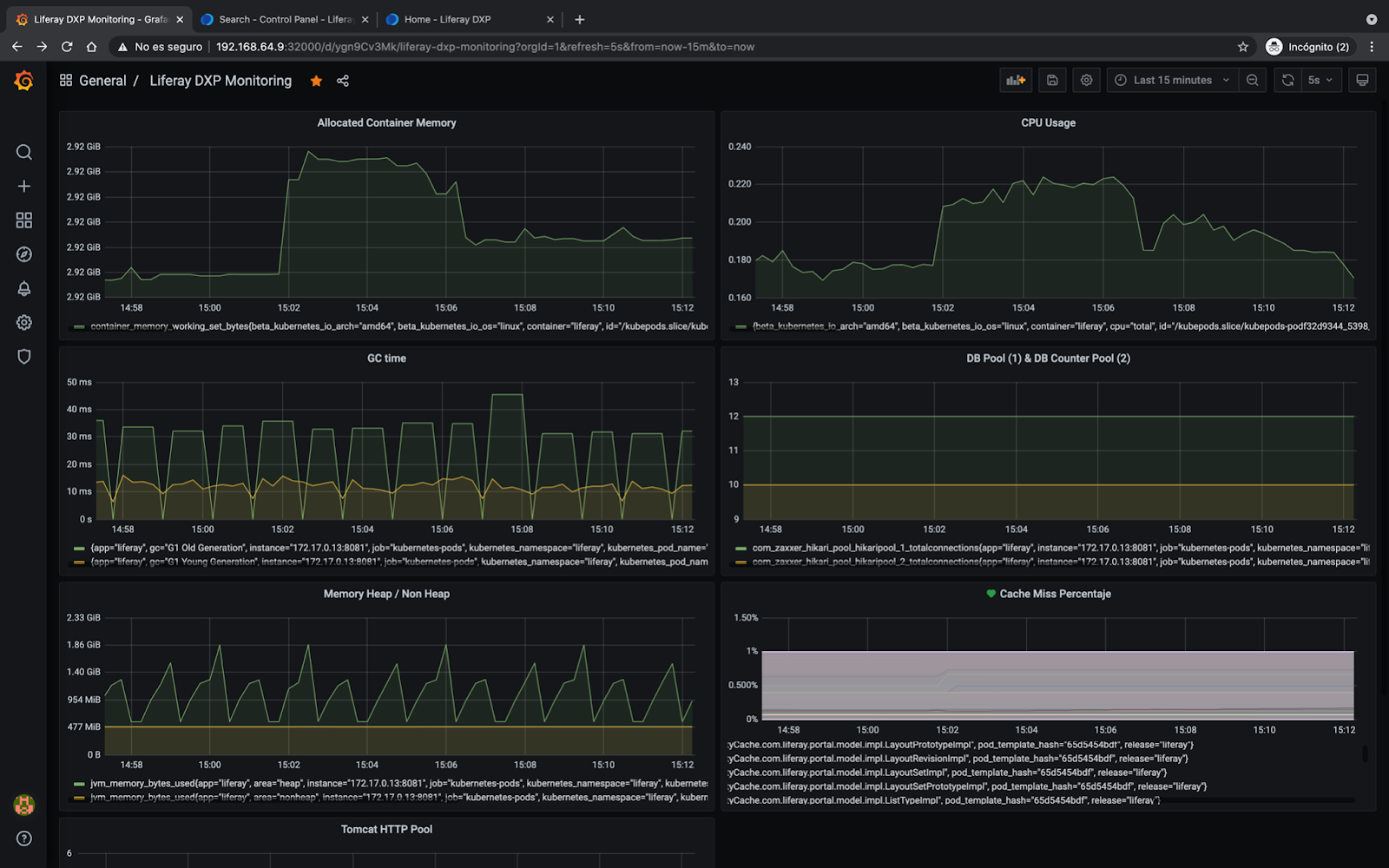
- Grafana is very powerful and highly customizable, so the graphics that you want to create will require some work time to leave them to the taste of the user who wants to exploit them. In the case of a Liferay Portal / DXP installation on k8s, I am monitoring container memory, container cpu usage, JVM memory usage and Garbage Collector time, database pools and connection pool HTTP, plus a dashboard to monitor the percentage of cache misses on Liferay Portal / DXP caches:
- It is possible to configure alerts for when a dashboard reaches a desired threshold. For example, when the cache misses percentage is higher than 90% for 5m, we will configure the following alert:
- We will be able to monitor the history of the alerts for the dashboard and obtain exact information of the moment in which the threshold was reached to analyze the problem.






Conclusion
Monitoring our Liferay Portal / DXP installation on Kubernetes, in a totally customized way, is possible thanks to Prometheus and Grafana. In addition, we will not only have a hot monitoring of the platform, we will also have a history that will help us to analyze its behavior in problematic situations.
Related Assets...
More Blog Entries...

